



Building a Kubeflow Pipeline Demo - Part Five
- Apr 1, 2019
- 9 min read
So, it all comes down to this... serving the model! URL's to be referenced are as follows...
https://forums.docker.com/t/how-can-i-run-docker-command-inside-a-docker-container/337/12 will show us how to push content into a TensorFlow Serving container running in the Virtual Box, but not in the KF Pipeline
https://towardsdatascience.com/deploy-your-machine-learning-models-with-tensorflow-serving-and-kubernetes-9d9e78e569db will show us how to actually do the push of our model into the TF Serving image.
I always like to undertake projects like this from the point of greatest unknown to the point of most certain, so let's start with putting up the TF Serving image and making sure we can access it from outside our MiniKF virtual box.
I want this to be a part of my snapshot on startup, so let's start by reverting our snapshot, adding the running image - which will be on the MiniKF machine but outside Kubernetes (for simplicity), and then re-taking a snapshot.
docker run -d --name serving_base tensorflow/serving
Seems to download and start something, so that's a good sign. Let's try hitting the REST port to verify there is something there...
Definitely no luck there - it returns a connection closed error. So, I'm a little stuck knowing whether this is the port not being mapped, or it needing a model in order to even start or something totally different. So, I'm going to try the more basic steps shown in this article first... crawling before I try to walk (or run).
After struggling a bit with the docker startup command there, I have realized that the lines need to be inverted a little. So, it is really...
docker run --mount type=bind,source="/tmp/tfserving/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu",target="/models/half_plus_two" -e MODEL_NAME=half_plus_two -p 8501:8501 -t tensorflow/serving
On running this, I am told that there is already something bound to 8501... hmmm... maybe the reason why we had issues above trying to access our original TF Serving? I'm going to restart the Virtual Box, then try again -- since I'm not sure if this is my own mess (a previous zombie TF Serving attempt) or something built into MiniKF.
A fresh start definitely works on port 8501 and - best of all - can be consumed from a browser running on my desktop out the MiniKF cluster, so we should definitely be able to put a simple web page out there to consume our model or - failing that - hit it with a simple Postman page. :-) . At this point, I take a snapshot of my MiniKF vbox image.
Now that we haver TensorFlow Serving running, we have to accomplish a few more steps. First, we need to figure out how to get an updated model over to the running server, then we have to tell the server to reload our image, so we can test it.
The reloading is explained at https://stackoverflow.com/questions/54440762/tensorflow-serving-update-model-config-add-additional-models-at-runtime, but we'll come to that next. First, we have to figure out how to copy our new model over there.
So, I start by adding a new step to my pipeline that will serve the content. I base the docker image on, simply, "docker:latest". This has all the bits for docker loaded into it, so I won't have to deal with installing Docker as a part of my image. However, a good part of what this has to do is load the model back in from Minio, and Minio's Python client installs via Python's PIP app, so I need to add both that and Python 3 itself. One interesting thing I discover at this point is that Docker's base image is Alpine, so I need to use the "apk add" command, in order to make this happen. After a few false starts, I am left with a Docker image with all the needed bits to connect to Minio and Docker.
Trying to run just the startup code, which imports the needed packages and instantiates Minio, leads me to my next challenge - numpy's latest version is incompatible with Alpine. Thankfully, there is an article here that explains how to amend my Dockerfile to use an older version. I have to hope that the numpy array format will be compatible between the older version and what I've got stored in my Minio instance at this point.
What I quickly realize is that this new image takes forever to build each time I change the code. Rather than tolerate this for the rest of this dev cycle, I am going to try something I've honestly not tried before. let me break everything except the source code out into a separate image. I create a "demobase" image with everything except my custom code, build that - which takes forever - then strip down my serve Dockerfile to base on that and just add my custom code. Rebuilding that happens in a flash. And running works... wow -- I should have done this a long time ago! Note to self: must re-factor the other images to do the same thing!
The rest of the coding up to the point of having the .h5 file retrieved and sitting on my new docker's local file system goes quite easily. And now I start to realize... something! Connecting this Docker image to the Docker image on the host would require passing a configuration file through to this Docker image But, this Docker image is actually going to be run by Kubeflow on Kubernetes, so the Docker runtime parameters are doubly removed from our configuration. Not only aren't they a part of Kubeflow, but they aren't a part of Kubernetes. So, I think... this is a needlessly-difficult way in which to try to achieve this. I will need a new design.
New design: let's have a Flask script running in the background on the same image as the Tensorflow Serving instance. Whenever someone calls that endpoint, it will be a signal to that Flask script to pull the model down fresh from Minio, unpack it in a folder on the local file system and tell Tensorflow to reload it.
It took a few hours, given my relative lack of previous experience with Python's Flask, but I ultimately got a server up and running and listening on port 5000. However, it is overriding the start of Tensorflow Serving, so I need to see if I can get both running at once. The suggestion seems to be to simply run Flask using a CMD instead of the ENTRYPOINT in the Docker image, so that the Tensorflow Serving image's default ENTRYPOINT to start itself is used. When I try that, it never seems to get to my CMD, I guess because TensorFlow's launch blocks the UI thread.
So, instead of that, I amend my runner.sh script to launch the same script that was previously used by Tensorflow Serving's DOCKERFILE (found on Github) after starting my Flask process in the background. Launched with the right docker command, this works fine...
docker run --mount type=bind,source="/tmp/tfserving/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_cpu",target="/models/half_plus_two" -e MODEL_NAME=half_plus_two -p 8501:8501 -p 5000:5000 -t dotnetderek/tfsbase:latest &
At this point, I had to take a quick detour because something broke with Minio. But, a quick revert of the Virtual Box and laying down my new TF Serving image again now has everything working together. Calling my REST endpoint causes the model to be downloaded onto the file system of the TF Serving image. We are so very close now - I just need to get that image into the format that TF Serving wants, then tell TF Serving to refresh itself.
At this point, I have the request Flask endpoint running, albeit with a couple of bugs I have to quash - so let me share some key learnings I had as I got this set up. First - a key debugging technique: actually having to spawn a TF Serving server to check every permutation of my fixes was extremely time-consuming, so I created a separate, stand-alone docker image called "quickrepro" that does nothing other than the retrieval and serialization part whenever I call it.
The thing that killed me more than anything else as a part of this is that the whole interaction between TF and Keras is greatly redesigned in TF 2.0, to the point that the old code samples no longer work for loading in a Keras model and re-saving it in the PB format that TF Serving needs. So, to get around that, I "downgraded" the image used by "tfbase" to be based on the image "tensorflow/serving:latest-devel". This immediately solved an error I was getting about "get_session" no longer being a method on the Keras back-end class.
However, this introduced another issue, because now the older deserializer didn't recognize a metadata entry in the file called "learning_rate". So, to fix this, I had to go back and re-base the training image on the same "tensorflow/serving:latest-devel" image. Once I did this and resaved the training model, my new tfsbase image deserialized fine when its URL is called. Furthermore, since I chose to deserialize to the place where TF Serving was spinning, complaining about not being able to find the model, as soon as I dropped this in, TF Serving recognized it and began being able to serve it!
I just have one bug to sort out now, which is that my Flask method is not re-entrant. It works fine the first time, but the second time it complains that the session has already been closed. This makes sense, considering that I use the line "with tf.keras.backend.get_session() as sess:", which will auto-close the session after the first run... so I need to figure out some way to tell it to create a new session on each REST call.
As a first step, I update my "quickrepro" Docker image to be simply use the tf.keras.backend.get_session() a couple of times in "with" blocks - to simulate 2 calls to my REST method. At first, it succeeds and I'm not sure why it isn't reproducing my REST error, but then I realize the "with" call itself does not use the session, so I add a statement to either block to retrieve the list of devices from the session -- just to have it do something to cause the session to be instantiated. And, as I suspected, this reproduces my issue.
Simply instantiating a new session and assigning it to the Keras backend seems to resolve this issue in the quickrepro Docker image, so I proceed to try the same approach in the main tfsbase image. And that resolves this error! But now we have another one: we can't export to a pre-existing directory. :-( . Maybe we can simply delete the directory and re-upload it? I'm skeptical though, because Tensorflow Serving is in the middle of serving the directory. We'll give it a try, though...
So - after I wrote the above, I was lucky enough to stumble upon something much, much better! It turns out that, when we get to the point of consuming this API via REST, if we don't specify a version number, TF Serving will automatically serve the latest one. The versions are arranged under the subdirectory in simple integer-named folders: 1, 2, 3, etc. So, rather than deleting any directories, I add some code to iterate through the exiting directories and create a directory with whatever integer as its name is next in the sequence (for example, a subdirectory called 4 if 1, 2 and 3 already exist).
Trying this worked even better than I had expected. Not only does this side-step the issue is trying to delete a directory out from under Tensorflow Serving, but it turns out that TF Serving even automatically loads newly-numbered directories when you load them into that subdirectory! :-) . No further work needed to do to force TF Serving to reload! :-)
After this, I installed Postman. I found the articles here and here very helpful in letting me put together the right format for the REST message, but I realized at the end that it was going to require me to define an image as a 28x28 array of floats and... that was going to be a bit much to copy out by hand. So, I elected to add a small piece of code to the preprocess step that output exactly the right JSON predict request for the first (maybe I'll make it random later) image in the test set. I take this and feed it into Postman and -- voila, it understands the message... simply thinks that the image should have been 784 x 128 instead of 28 x 28. I am completely stumped. :-(
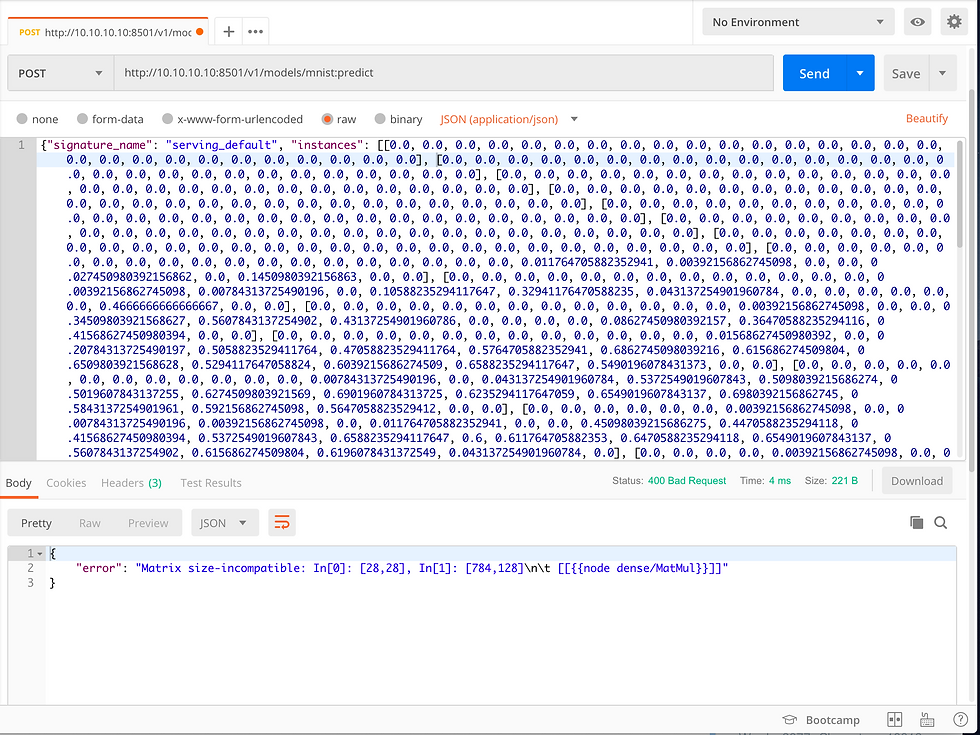
This began a long period of "wandering in the wilderness" for me yesterday. At one point, I quite despaired of ever getting this to work but one of the things I tried - although quite ill-conceived - led me to notice that my Numpy arrays were NOT the shape I expected them to be. This led me to 2 crucial discoveries of things that have been broken ever since step 1. First, I never performed the reshaping of the image tensors as a part of their preprocessing, which was essential to separate them into separate images. Adding that to the preprocessing step seemed to get the data into the right shape for that step, but it was still mangled by the next step.
Just for giggles, I decided to try saving these Numpy arrays and immediately retrieving them to test their shapes and - sure enough - Numpy wasn't saving them properly. After much investigation and re-coding, the solution here was to move everything over to Pickle, which is a technology built into Python for saving objects. Moving over to this helped immediately, but an important point to note is that one must explicitly request Python to use the most recent kind of object serialization in order for this to work properly with multi-dimensional Numpy arrays - at least in my experience.
Having made this change and flowed it through, the only other point of note was that I changed the nature of the model in such a way that I found I have to recompile the model in the evaluate step now, because the TensorFlow optimizer can not be serialized properly. No biggie -- line added and...
One last thing... the message format given is for the identification of a single object. If you pass it into Postman "as is", it will complain that you are missing the 4th dimension. The solution is simply to enclose the image array in an additional pair of enclosing [] , and then, when you pass it in, you will get the following prediction.

And this is what success looks like. :-)
Comments